Kategoriler
Son Yazılar
Makale Nasıl Yazılır ?
Kadro Başvuru Değerlendirme ve Sıralama Sistemi v1.0
Grobeton Metraj ve Bayındırlık Poz Numarası
Banka Otomasyonu (C Programlama)
Php Connections
Hayallerin Gücü
Labview Programlama
Sample: Classification and Clustering
News Agency Management System
Java Connections
Java Server Pages Etiketleri
Android Programlama 1: Eclipse ve Android SDK
Değerlilerim





Sınıflama ve Kümeleme Algoritmaları
08 Ekim 2013 tarihinde Emre ÇİNTAŞ tarafından yazılmıştır.
Veri madenciliğinde classification(sınıflandırma) ve clustering(kümeleme) algoritmaları oldukça önemlidir bu iki algoritmayla verilerden anlamlı sentezler yapabiliriz.
Classification(Sınıflama)
Veri setinde bulunan her örneğin bir dizi niteliği vardır ve bu niteliklerden biri de sınıf bilgisidir. Hangi sınıfa ait olduğu bilinen nesneler (öğrenme kümesi- training set) ile bir model oluşturulur Oluşturulan model öğrenme kümesinde yer almayan nesneler (deneme kümesi- test set) ile denenerek başarısı ölçülür.
Clustering(Kümeleme)
Genelde K-Means algoritması kullanılır ve veri kümesini birbirinden ayrık kümelere böler. K değişkeninin başta belirtilmesi gerekir.
K-means kümeleme algoritmasının adımları;
Belirlenecek küme sayısı k seçilir. Veri kümesinden k adet örnek başlangıç küme merkezleri olarak rastgele seçilir. Öklid mesafesi kullanılarak kalan örneklerin en yakın olduğu küme merkezleri belirlenir. Her küme için yeni örneklerle küme merkezleri hesaplanır. Eğer kümelerin yeni merkez noktaları bir önceki merkez noktaları ile aynı ise işlem bitirilir. Değilse yeni küme merkezleri ile 3 adımdan itibaren işlemler tekrarlanır.
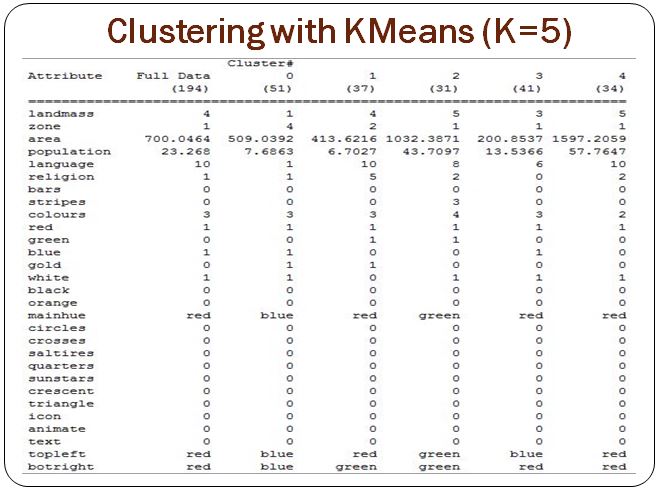
Bir sonraki yazımda 4.sınıf 1.dönem, Data Mining dersinde yaptığım "194 ülkenin bayrak renklerine göre hangi dil ve dinin baskın olduğu bilgisinin sınıflama ve kümeleme metodlarıyla bulunması" konulu proje örneğini yayınlayacağım.
Ekran görüntüsü: